The Problem
In many companies, only a small proportion of the data is stored in a structured format i.e. in databases or spreadsheets. A very large proportion may be found in unstructured formats such as documents, reports, emails etc… The issue here is that it makes processing and analysing this data very difficult. If somebody wanted a computer to analyse a company’s growth in profit based on a series of reports it would struggle. This is because computers follow a very specific set of languages when performing operations. A single digit syntax error is enough to stop a 3000 line program from running. Human language, on the other hand, has a wide range of discrepancies such as words with multiple meanings, accents, strange word play and diverse vocabulary. This is why it is called a ‘natural language.’ Recent technological advancement have made such challenges surmountable.
How do Computers Interpret Text?
Firstly computers, just like humans, are able to group words into their various categories. The nine ‘parts of speech’ include verbs, adverbs, adjectives, nouns, pronouns, conjunctions, interjections, articles and prepositions. Each of these can be split into smaller subcategories e.g. proper, abstract and concrete nouns. Already the computer has some understanding of the words. However, as you will see in the following sentence, words can have multiple meanings and belong to multiple categories:
“I left my phone on the left side of the room”
Consequently, computers also need to have a good understanding of grammar. Luckily though, the rules we learned in primary school are still apply and can be used by the computer to interpret the sentence. Such rules look like this:
-
A sentence = [noun phrase] + [verb phrase]
-
A noun phrase = [article] + [noun] or
-
A noun phrase = [adjective] + [noun] etc...
In our sentence example above,“I left my phone” is this verb phrase which is made up nouns, pronouns and verbs. We can visualize this through what is known as a ‘parse tree’ which splits up the components of a sentence. The same can be done for the next part of the sentence and this is how computers can understand text.
How do Computers Generate Text?
Being able to understand a given string of text is one thing, however being able to produce grammatically correct sentences adds a whole new dimension to the problem. Luckily the same phrase rules which apply to reading text also apply to writing text. However another component is needed: An understanding of the words it uses.
To accomplish this, computers are able to store very large webs of semantic information as shown in the diagram below:
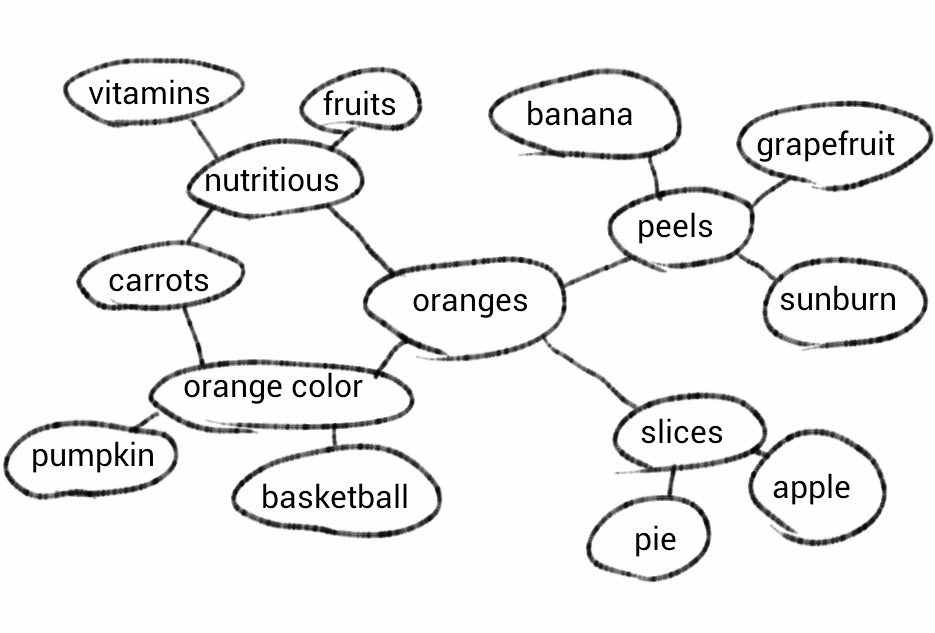
These webs provide meaningful relationships between words and also tell the computer what type of word they are (e.g. noun, verb etc…). Google’s version is named ‘knowledge graph’ and by the end of 2016 stored 70 billion facts and relationships about various entities. Computers can therefore use word association and rules to produce natural language. Chatbots were a great example of early text generation software. However often these programs were heavily hard coded to deal with a lot of contingencies. This lead to repetitive responses and a decline in so called intelligence. Modern approaches, however, utilise the wonderful technology behind machine learning to train algorithms to a great degree of accuracy. Thankfully there is an awful lot of text out there for computers to learn from!
How do Computers Interpret Sound?
Speech recognition is an entirely new aspect to the problem and has become much more useful in today’s evolving world. Technology like Alexa and Siri are widely used by millions all over the world. However the journey to achieving feasible speech recognition has been quite a long one and for a while had very little impact. Early engines could recognise a finite number of numbers and words however this had little use as the average person could still read and write much more much quicker. Just like with text generation software, the introduction of machine learning was a turning point in the technology’s history. Moreover, massive pools of data to learn from (such as phone calls, songs and radio recordings) made its progress possible. However we still haven’t answered the initial question.
To decipher a sound, a simple analogue time-amplitude recording is not enough. Instead a spectrogram is used. In spectrograms, the magnitude of different frequencies are recorded. On a graph this can be seen where the greater the magnitude, the brighter the colour:
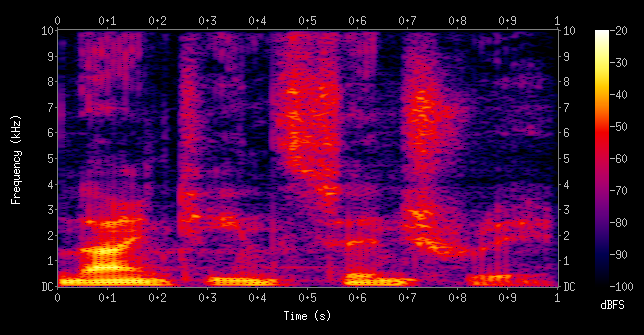
Different sounds (vowels and consonants) now have different patterns and can be interpreted by the computer. These sounds are actually called ‘phonemes’ and there are 44 for a computer to recognise. The computer must also be able to deal with discrepancies in the sound e.g. accents and slang. Language models, frequency statistics and word association can therefore also be used to produce the correct sentence based on the probabilities of what the word most likely was. Once a sound has been converted into text, it can be processed in the exact same way we saw earlier.